

https://medium.com/solana-labs/pipelining-in-solana-the-transaction-processing-unit-2bb01dbd2d8f
よくわからんけど、取引の実行処理、その検証のフェーズがあって、取引の実行処理の実行フェーズのことをTPUといっているようだ。
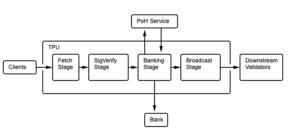
Solanaが世界初のWebスケールのブロックチェーンになるために必要な1秒未満の確認時間とトランザクション容量を取得するには、コンセンサスをすばやく形成するだけでは不十分です。チームは、トランザクションの大規模なブロックを迅速に検証すると同時に、ネットワーク全体でそれらを迅速に複製する方法を開発する必要がありました。これを実現するために、Solanaネットワークでのトランザクション検証のプロセスでは、パイプラインと呼ばれるCPU設計で一般的な最適化を広範囲に使用します。
パイプライン化は、一連のステップで処理する必要のある入力データのストリームがあり、それぞれに異なるハードウェアが関与している場合に適切なプロセスです。これを説明する典型的な比喩は、洗濯物を数回順番に洗濯/乾燥/折りたたむ洗濯機と乾燥機です。洗濯は乾燥前、乾燥は折り畳み前に行う必要がありますが、3つの操作はそれぞれ別のユニットで行われます。
効率を最大化するために、ステージのパイプラインを作成します。洗濯機を1つの段階、乾燥機を別の段階、折り畳みプロセスを3番目の段階と呼びます。パイプラインを実行するには、最初の負荷が乾燥機に追加された直後に、洗濯機に2番目の負荷の洗濯物を追加します。同様に、2番目の負荷が乾燥機にあり、最初の負荷が折りたたまれた後、3番目の負荷が洗濯機に追加されます。このようにして、3回分の洗濯を同時に進めることができます。無限の負荷が与えられると、パイプラインはパイプラインの最も遅いステージの速度で一貫して負荷を完了します。
すなわち、複数のコンピューターを平行に稼働させて、段階の異なるものを分担して同時並行的に早く終わらせるのがパイプラインか。
「すべてのハードウェアを常にビジー状態に保つ方法を見つける必要がありました。これがネットワークカード、CPUコア、およびすべてのGPUコアです。そのために、CPU設計からページを借りました」とSolanaの創設者でCTOのGregFitzgerald氏は説明します。「ソフトウェアで4ステージのトランザクションプロセッサを作成しました。これをTPU、トランザクション処理ユニットと呼んでいます。」

Solanaネットワークでは、パイプラインメカニズム(トランザクション処理ユニット)は、カーネルレベルでのデータフェッチ、GPUレベルでの署名検証、CPUレベルでのバンキング、およびカーネルスペースでの書き込みを介して進行します。TPUがバリデーターにブロックを送信し始めるまでに、TPUはすでに次のパケットのセットでフェッチされ、署名を検証し、トークンのクレジットを開始します。
バリデーターノードは、2つのパイプラインプロセスを同時に実行します。1つはTPUと呼ばれるリーダーモードで使用され、もう1つはTVUと呼ばれるバリデーターモードで使用されます。どちらの場合も、パイプライン化されるハードウェアは同じであり、ネットワーク入力、GPUカード、CPUコア、ディスクへの書き込み、およびネットワーク出力です。そのハードウェアで何をするかは異なります。TPUは元帳エントリを作成するために存在しますが、TVUはそれらを検証するために存在します。
「署名の検証がボトルネックになることはわかっていましたが、GPUにオフロードできるのはこのコンテキストフリーの操作であることもわかっていました」とFitzgersald氏は言います。「この最もコストのかかる操作をオフロードした後でも、ネットワークドライバーとの対話や、同時実行を制限するスマートコントラクト内のデータ依存関係の管理など、さらに多くのボトルネックがあります。」
オフロードとは?
オフロードとは、(積荷を)降ろす、解放する、などの意味を持つ英単語。ITの分野では、あるシステムの負荷を他の機器などが肩代わりして軽減する仕組みを指す。
GPUとは?単純作業を超高速で処理できる。
この4ステージパイプラインでのGPU並列化の間、いつでも、SolanaTPUは50,000トランザクションを同時に進行させることができます。「これはすべて、5000ドル未満の既製のコンピューターで実現できます」とフィッツガーランドは説明します。「一部のスーパーコンピューターではありません。」
solanaは将来的にはGPUを使いたい(し、それが出来るコードで書かれている。が今は5000ドル以下のパソコンでも十分早いよということを言っている。
GPUがSolanaのトランザクション処理ユニットにオフロードされると、ネットワークが単一ノードの効率に影響を与える可能性があります。これを達成することは、創業以来ソラナの目標でした。
「次の課題は、どういうわけかリーダーノードからすべてのバリデーターノードにブロックを移動し、ネットワークを混雑させずにスループットをクロールにもたらさない方法でそれを行うことです」とフィッツジェラルドは続けます。「そのために、タービンと呼ばれるブロック伝播戦略を考え出しました。
「Turbineを使用して、Validatorノードを複数のレベルに構造化します。各レベルはその上のレベルの少なくとも2倍のサイズです。この構造、これらの明確なレベルを持つことにより、確認時間はツリーの高さに比例し、ツリー内のノードの数には比例しなくなります。これははるかに長くなります。ネットワークのサイズが2倍になるたびに、確認時間にわずかな増加が見られますが、それだけです。」
パイプラインのような技術的な実装に加えて、SolanaのWebスケールのブロックチェーン機能を可能にするいくつかの重要な革新があります。それらすべてをより深く理解するには、Solanaブログでそれらについて読むことができます。
タービンブロックの伝播
タービンって何?
Solanaクラスターは、Turbineと呼ばれる多層ブロック伝播メカニズムを使用して、最小限の重複メッセージでトランザクションシュレッドをすべてのノードにブロードキャストします。クラスタは、近隣と呼ばれるノードの小さなコレクションに分割されます。各ノードは、受信したデータを近隣の他のノードと共有し、データを他の近隣のノードの小さなセットに伝播する責任があります。このように、各ノードは少数のノードと通信するだけで済みます。
そのスロットの間に、リーダーノードは最初の近傍(レイヤー0 )のバリデーターノード間でシュレッドを分配します。各バリデーターはその近隣内でデータを共有しますが、次のレイヤー(レイヤー1 )のいくつかの近隣の1つのノードにシュレッドを再送信します。レイヤー1ノードはそれぞれ、近隣のピアとデータを共有し、クラスター内のすべてのノードがすべてのシュレッドを受信するまで、次のレイヤーのノードなどに再送信します。
近隣の割り当て-加重選択#
データプレーンのファンアウトが機能するためには、クラスター全体がクラスターを近隣に分割する方法について合意する必要があります。これを実現するために、認識されたすべてのバリデーターノード(TVUピア)がステークによってソートされ、リストに格納されます。次に、このリストにさまざまな方法でインデックスが付けられ、近隣の境界を把握してピアを再送信します。たとえば、リーダーはレイヤー0を構成する最初のノードを選択するだけです。これらは自動的に最高の利害関係者になり、最も重い票が最初にリーダーに戻ることができます。レイヤー0と下位レイヤーのノードは、同じロジックを使用して、隣接ノードと次のレイヤーのピアを検索します。
データプレーン?コントロールプレーンの設定を引き継ぐ機器のことらしい
https://www.psid.co.jp/news/tag/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%97%E3%83%AC%E3%83%BC%E3%83%B3/
攻撃ベクトルの可能性を減らすために、各シュレッドは近隣のランダムなツリーを介して送信されます。各ノードは、クラスターを表す同じノードのセットを使用します。リーダーID、スロット、およびシュレッドインデックスから派生したシードを使用して、各シュレッドのセットからランダムツリーが生成されます。
レイヤーと近隣構造#
現在のリーダーは、ほとんどのDATA_PLANE_FANOUTノードに最初のブロードキャストを行います。このレイヤー0がクラスター内のノードの数よりも小さい場合、データプレーンのファンアウトメカニズムにより、下にレイヤーが追加されます。後続のレイヤーは、これらの制約に従ってレイヤー容量を決定しますDATA_PLANE_FANOUT。各近隣にはノードが含まれます。レイヤー0は、ファンアウトノードを持つ1つの近隣から始まります。追加の各レイヤーのノード数は、ファンアウトの係数で増加します。
上記のように、レイヤー内の各ノードは、クラスター内のすべてのTVUピアではなく、隣接ノードと一部の次のレイヤーネイバーフッドの正確に1つのノードにシュレッドをブロードキャストするだけで済みます。これについて考える良い方法は、レイヤー0はファンアウトノードを持つ1つの近隣から始まり、レイヤー1はファンアウトノードを持つ1つの近隣を追加し、レイヤー2にはそれぞれファンアウトノードがありfanout * number of nodes in layer 1ます。
このように、各ノードは最大数の2 * DATA_PLANE_FANOUT - 1ノードと通信するだけで済みます。
次の図は、リーダーがファンアウト2のシュレッドをレイヤー0のネイバーフッド0に送信する方法と、ネイバーフッド0のノードが互いにデータを共有する方法を示しています。

次の図は、Neighborhood0がNeighborhood1と2にどのようにファンアウトするかを示しています。
ファンアウトはCMOSロジックICの出力端子に接続可能なCMOSロジックICの入力端子の数を表します。
うーんわからん。

最後に、次の図は、ファンアウトが2の2層クラスターを示しています。

構成値#
DATA_PLANE_FANOUT-レイヤー0のサイズを決定しますDATA_PLANE_FANOUT。後続のレイヤーは係数で成長します。近隣のノードの数は、ファンアウト値と同じです。新しい近隣が追加される前に、近隣は定員に達します。つまり、近隣が満杯でない場合は、それが最後の近隣である必要があります。
現在、構成はクラスターの起動時に設定されます。将来的には、これらのパラメーターはオンチェーンでホストされる可能性があり、クラスターサイズの変更に応じてその場で変更できるようになります。
必要なFECレートの計算#
Turbineは、バリデーター間のパケットの再送信に依存しています。再送信により、ネットワーク全体のパケット損失が悪化し、各ホップでパケットが宛先に到達できない可能性が高くなります。FECレートでは、ネットワーク全体のパケット損失と伝搬深度を考慮する必要があります。
シュレッドグループは、相互に再構築するために使用できるデータとコーディングパケットのセットです。各シュレッドグループには、FECレートを超える失敗するパケット数の可能性に基づいて、失敗する可能性があります。バリデーターがシュレッドグループの再構築に失敗した場合、ブロックを再構築することはできず、バリデーターはブロックを修正するために修復に依存する必要があります。
シュレッドグループが失敗する確率は、二項分布を使用して計算できます。FECレートが16:4、の場合、グループサイズは20であり、グループが失敗するには、少なくとも4つのシュレッドが失敗する必要があります。これは、20個のうち4個以上のトレイルが失敗する確率の合計に相当します。
タービンで成功するブロックの確率:
- パケット障害の確率:
P = 1 - (1 - network_packet_loss_rate)^2 - FECレート:
K:M - 試行回数:
N = K + M - シュレッドグループの失敗率:
S = SUM of i=0 -> M for binomial(prob_failure = P, trials = N, failures = i) - ブロックごとのシュレッド:
G - ブロック成功率:
B = (1 - S) ^ (G / N) iN回の試行でPの確率を持つ正確な結果の二項分布は、次のように定義されます。(N choose i) * P^i * (1 - P)^(N-i)
例えば:
- ネットワークパケット損失率は15%です。
- 50k tpsネットワークは、1秒あたり6400シュレッドを生成します。
- FECレートは、ブロックあたりの合計シュレッドをFEC比率だけ増加させます。
FECレートの場合: 16:4
G = 8000P = 1 - 0.85 * 0.85 = 1 - 0.7225 = 0.2775S = SUM of i=0 -> 4 for binomial(prob_failure = 0.2775, trials = 20, failures = i) = 0.689414B = (1 - 0.689) ^ (8000 / 20) = 10^-203
FEC率が 16:16
G = 12800S = SUM of i=0 -> 32 for binomial(prob_failure = 0.2775, trials = 64, failures = i) = 0.002132B = (1 - 0.002132) ^ (12800 / 32) = 0.42583
FEC率が 32:32
G = 12800S = SUM of i=0 -> 32 for binomial(prob_failure = 0.2775, trials = 64, failures = i) = 0.000048B = (1 - 0.000048) ^ (12800 / 64) = 0.99045
近所#
次の図は、異なるレイヤーの2つの近隣がどのように相互作用するかを示しています。近隣を不自由にするには、上記の近隣からの十分なノード(イレイジャーコード+1 )が失敗する必要があります。各近隣は上位層の近隣の複数のノードからシュレッドを受信するため、データが不完全になるには、上位層で大きなネットワーク障害が発生する必要があります。




